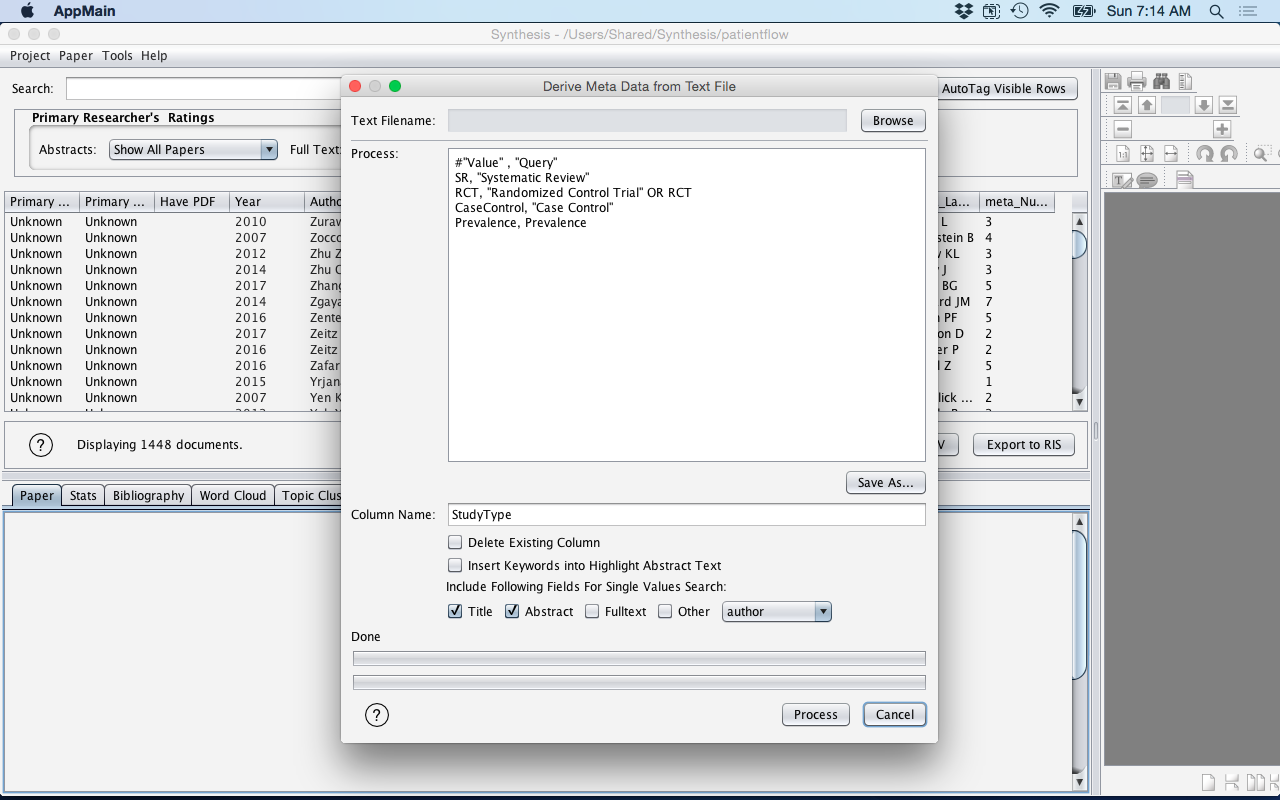
Derive Meta Data from Text File
Derives custom columns of user-generated topics from several fields (i.e. title, abstract, fulltext, affliation) based upon keywords and phrases. Uses automation to identify keywords in the reference and full-text article.
Synthesis Main Window Menu: Tools > Derive Meta Data from Text File
Synthesis allows custom columns to be created based upon a set of user-specificed keyword search rules. The power of this feature is that it often allows a type of analysis to be performed that realistically could not be done without automation.
Some previous examples where this approach has been used include:
- Deriving which Statistics were presented in over 600 full-text PDFs [reference].
- Deriving the Type of Paper a reference was (i.e. Prevalence, Assocaition, etc.) from the Title in several thousand references [reference].
The format of the Text File is as follows:
- # is the start of a comment (i.e. not to be processed)
- One row per rule
- value, query : is the rule format. Value is the value to be recorded in the
reference's Column (i.e. Column Name defined below) when a match is found. The
query is what Synthesis is identifying in the references. The query can use
boolean logic (AND, OR, NOT, and rounded brackets).
- Note: the value and the query need to be separated by a comma (i.e. RCT, "Randomized Control Trial").
- value: If only a value is provided, then the setting under the below "Include following fields for Single Value Search" are associated with the value. (i.e. if Title and Abstract are checked off, and only a value is provided, such as RCT, the resulting Synthesis query would be: title:RCT OR abstract:RCT).
The process for using the Derive Meta Data from Text File is as follows:
- If a previous Derive Meta Data text file has already been created, it can be imported by using the Browse button. If not, in the Process text editor, new rules can be added.
- The Process text editor displays the rules to be preformed. These rules can be
edited and modified.
- The contents of the Process text area can be saved using the "Save As..." button.
- Enter the Column Name to be created in which the value(s) will be recorded for each reference.
- The "Insert Keywords into Highlight Abstract Text" checkbox will insert the value(s) into the Project Settings Highlight Abstract Keywords sub-window (see Project Settings).
- The "Include Following Fields for Single Value Search" allows the single value keyword to be only associated with the Title, Abstract, Fulltext, or Other (author, journal, afflication) fields.
- Click the Process button to Derive the Meta Data.
Figure: Derive Meta Data from File
| Parameter | Description |
|---|---|
| Text Filename | The name of the Text File to import using the Browse button. |
| Process | A text editor that displays all the rules to be processed. |
| Save As... | Saves the content of the Process text editor. |
| Column Name | The name of the column that will be created. |
| Delete Existing Column | If the column already exists, this option will delete the column and then overwrite it. |
| Insert Keywords and Highlight Abstract Text | Insert the value(s) into the Project Settings Highlight Abstract Keywords sub-window (see Project Settings). |
| Include the Following Fields for Single Value Search | Allows single value keywords in the Process text editor to be only associated with the Title, Abstract, Fulltext, or Other (author, journal, afflication) fields. |
| Value | Query |
|---|---|
| SR | "Systematic Review" |
| RCT | "Randomized Control Trial" OR RCT |
| CaseControl | "Case Control" |
| LitReview | "systematic review" OR "scoping review" OR "rapid review" |
| SRCanadaMalawi | "systematic review" AND (Canada OR Malawi) |
| SRCanadaNotMalawi | "systematic review" AND (Canada AND NOT Malawi) |
Validation: an important aspect of using this approach is to provide some sort of
validation. One approach is to do perform a 10% random sample of the data and have a
human perform the same data extraction/data indentification and then compare the human
against the Derive Meta Data keywords, and perform a Kappa Score at the end to determine
level of agreement. Synthesis has several built in features to help with this. The
following is a suggested workflow for validating user-defined Derive Meta Data:
- Create a Custom Column [TODO] which defines Derive Meta Data result your into a binary Yes or No classification. For example, if you had the Derive Meta Data identifying "Randomized Control Trial", you could create a Custom Column called "RCT_Auto" (for RCT Automated) and classify that column as "Yes" or "No" values.
- Create a Random Sample column of 10%. See Sample Column
- Filter on the "Yes" values in the Random Sample column (see Filter Cells), so that only the 10% sample is being displayed in the Synthesis Main Window.
- Create a Custom Column (see [TODO]) to be used by the human to perform the same task of identifying the keywords. A suggested name may be "RCT_Manual". Record "Yes" or "No" in the column.
- Finally, compare the Derive Meta Data automated approached with the Human Data Extracted manual approach (i.e. RCT_Auto vs RCT_Manual) by using the Kappa calculator (see Kappa Calculator). Note: Ensure you still have the search filter displaying the random sample column "Yes" values.